[머신러닝/사이킷런] 앙상블 학습(분류): 스태킹(Stacking)
학습 자료: 파이썬 머신러닝 완벽 가이드(개정2판), 위키북스
개요
개별 알고리즘의 예측 결과 데이터셋을 최종적인 메타 데이터셋으로 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고, 테스트 데이터를 기반으로 다시 최종 예측을 수행
스태킹 모델의 핵심은 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 피처 데이터셋과 테스트용 피처 데이터셋을 만드는 것
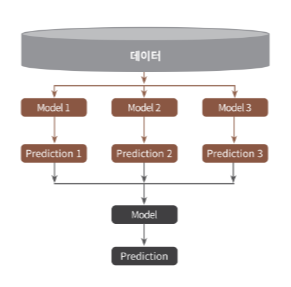
두 종류의 모델 필요
1) 개별적인 기반 모델: 2~3개를 넘어서는 많은 개별 모델이 필요
2) 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델

M개의 로우, N개의 피처(컬럼)를 가진 데이터셋에 총 3개의 기반 모델을 활용
1. 모델별로 각각 학습시킨 뒤 예측을 수행 -> 각각 M개의 로우를 가진 1개의 레이블 값 도출
2. 모델별로 도출된 예측 레이블 값을 다시 합해서(스태킹) 새로운 데이터셋 생성
3. 스태킹된 데이터셋에 대해 최종 모델을 적용해 최종 예측 수행
CV 세트 기반의 스태킹
메타 모델에서 최종 학습할 때 레이블 데이터셋으로 학습 데이터가 아닌 테스트용 레이블 데이터셋을 기반으로 학습할 시 과적합 문제가 발생할 수 있음
따라서, 최종 메타 모델을 위한 데이터셋을 만들 때 교차 검증 기반으로 예측된 결과 데이터셋을 이용



Step 1
(N=3)
1. 원본 학습용 데이터를 3개의 폴드로 나누되, 2개의 폴드는 학습용, 나머지 1개의 폴드는 검증용으로 분리
2. 학습용 2개의 폴드를 기반으로 개별 모델을 학습시킴
3. 학습된 개별 모델을 검증 폴드 1개 데이터로 예측하고 그 결과를 저장
4. 이러한 로직을 3번 반복하며 학습 데이터와 검증 데이터셋을 변경해가며 학습 후 예측 결과를 별도로 저장
-> 이렇게 만들어진 예측 데이터는 메타 모델을 학습시키는 학습 데이터로 사용
5. 2개의 학습 폴드 데이터로 학습된 개별 모델은 원본 테스트 데이터를 예측하여 예측값 생성
6. 이러한 로직을 3번 반복하며 이 예측값의 평균으로 최종 결괏값을 생성
-> 이를 메타 모델을 위한 테스트 데이터로 사용
Step 2
1. 각 모델들이 스텝 1로 생성한 학습과 테스트 데이터를 모두 합쳐 최종적으로 메타 모델이 사용할 학습 데이터와 테스트 데이터 생성
2. 메타 모델이 사용할 최종 학습 데이터와 원본 데이터의 레이블 데이터를 합쳐 메타 모델을 학습한 후에 최종 테스트 데이터로 예측을 수행
3. 최종 예측 결과를 원본 테스트 데이터의 레이블 데이터와 비교해 평가