
학습 자료: 파이썬 머신러닝 완벽 가이드(개정2판), 위키북스
Grid Search 방식의 단점
하이퍼 파라미터 튜닝 중 Grid Search 방식은 튜닝해야 할 하이퍼 파라미터 개수가 많을 경우 최적화 수행 시간이 오래 걸린다는 단점이 존재한다. 여기에 개별 하이퍼 파라미터 값의 범위가 넓거나 학습 데이터가 대용량일 경우에는 최적화 시간이 더욱 늘어나게 된다.
XGBoost나 LightGBM 등 하이퍼 파라미터 개수가 다른 알고리즘에 비해 많은 모델은 실무의 대용량 학습 데이터에 Grid Search 방식을 적용하면 많은 시간이 소요될 수 있다.
베이지안 최적화
개요
목적 함수 식을 제대로 알 수 없는 블랙 박스 형태의 함수에서 최대 또는 최소 함수 반환 값을 만드는 최적 입력값을 가능한 적은 시도를 통해 빠르고 효과적으로 찾아주는 방식
베이지안 확률에 기반을 두고 있는 최적화 기법
베이지안 확률이란?
새로운 데이터 B가 주어졌을 때, 기존에 알고 있던 사전 확률 P(A)을 업데이트하여 사후 확률 P(A∣B)을 계산하는 과정

베이지안 최적화는 새로운 데이터를 입력받았을 때 최적 함수를 예측하는 사후 모델을 개선해 나가면서 최적 함수 모델을 만들어 낸다.
베이지안 최적화를 구성하는 두 가지 중요 요소
1. 대체 모델(Surrogate Model): 획득 함수로부터 최적 함수를 예측할 수 있는 입력값을 추천 받은 뒤 이를 기반으로 최적 함수 모델을 개선
2. 획득 함수(Acquisition Function): 개선된 대체 모델을 기반으로 최적 입력값을 계산
(하이퍼 파라미터 튜닝에서는 입력값=하이퍼 파라미터)
=> 대체 모델은 획득 함수가 계산한 하이퍼 파라미터를 입력받으면서 점차적으로 개선되며, 개선된 대체 모델을 기반으로 획득 함수는 더 정확한 하이퍼 파라미터를 계산
과정
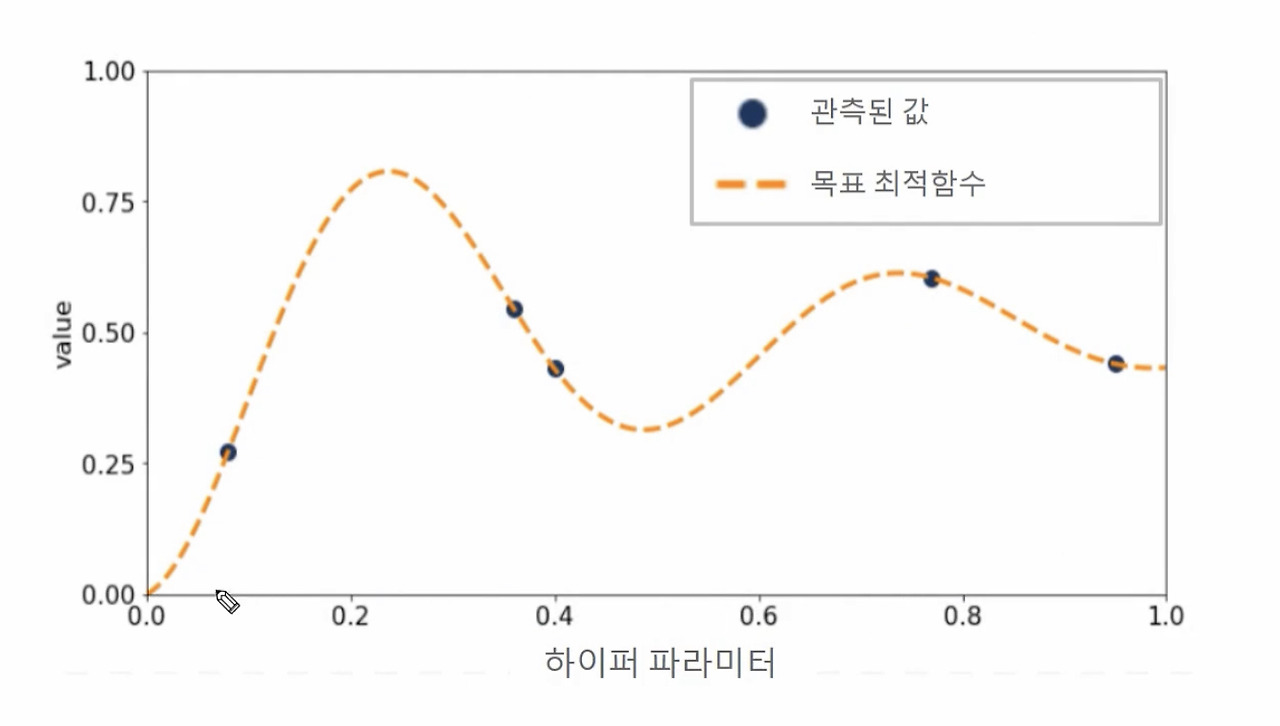
Step 1: 최초에는 랜덤하게 하이퍼 파라미터들을 샘플링하고 성능 결과를 관측. 아래 그림에서 검은색 원은 특정 하이퍼 파라미터가 입력되었을 때 관측된 성능 지표 결괏값을 뜻하며 주황색 사선은 찾아야 할 목표 최적함수.
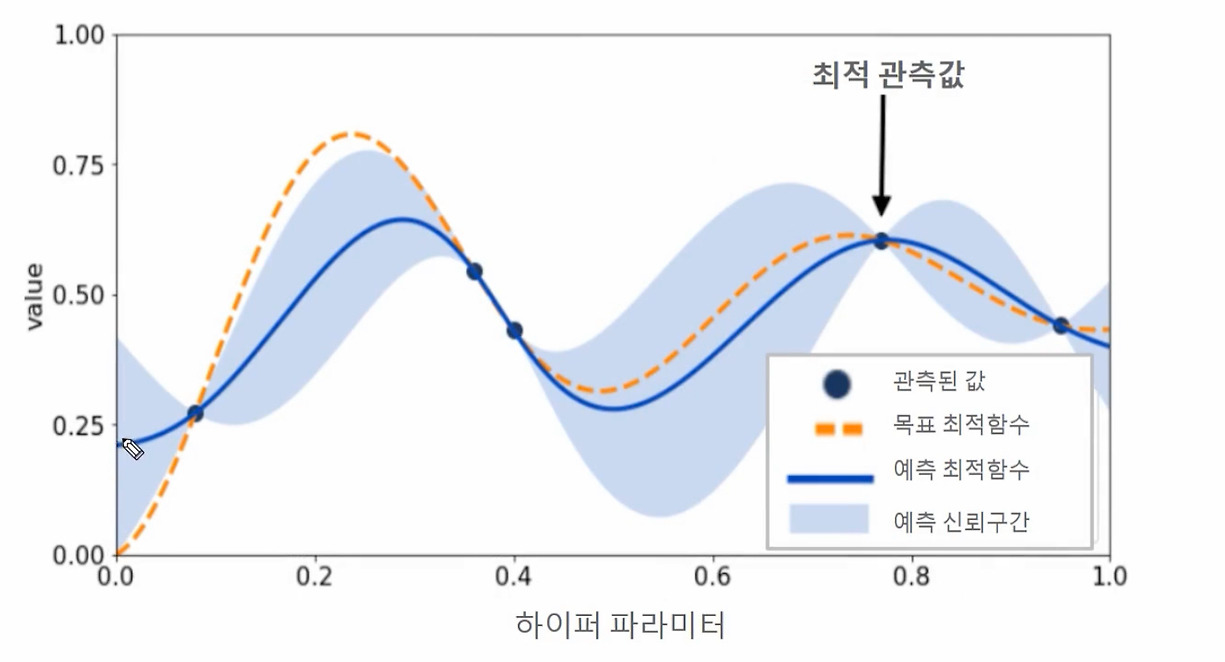
Step 2: 관측된 값을 기반으로 대체 모델은 최적 함수를 추정. 아래 그림에서 파란색 실선은 대체 모델이 추정한 최적 함수. 옅은 파란색으로 되어 있는 영역은 예측된 함수의 신뢰 구간. 최적 관측값은 y축 value에서 가장 높은 값을 가질 때의 하이퍼 파라미터
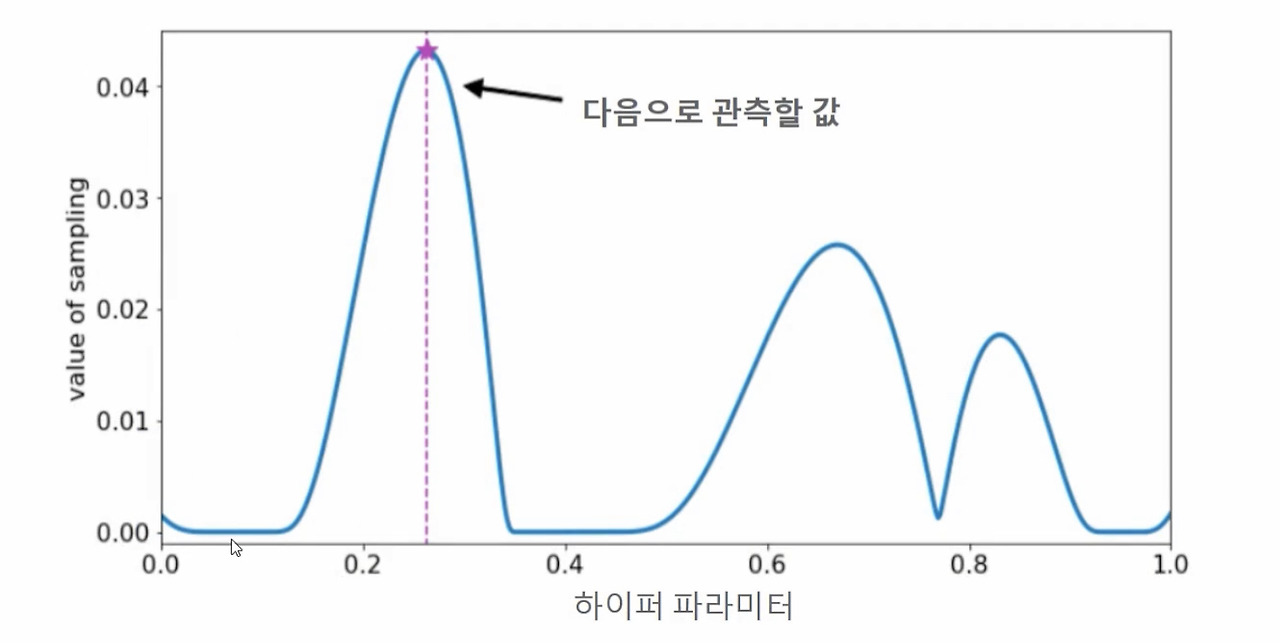
Step 3: 추정된 최적 함수를 기반으로 획득 함수는 다음으로 관측할 하이퍼 파라미터 값을 계산. 획득 함수는 이전의 최적 관측값보다 더 큰 최댓값을 가질 가능성이 높은 지점을 찾아서 다음에 관측할 하이퍼 파라미터를 대체 모델에 전달.
Step 4: 획득 함수로부터 전달된 하이퍼 파라미터를 수행하여 관측된 값을 기반으로 대체 모델은 갱신되어 다시 최적 함수를 예측 추정
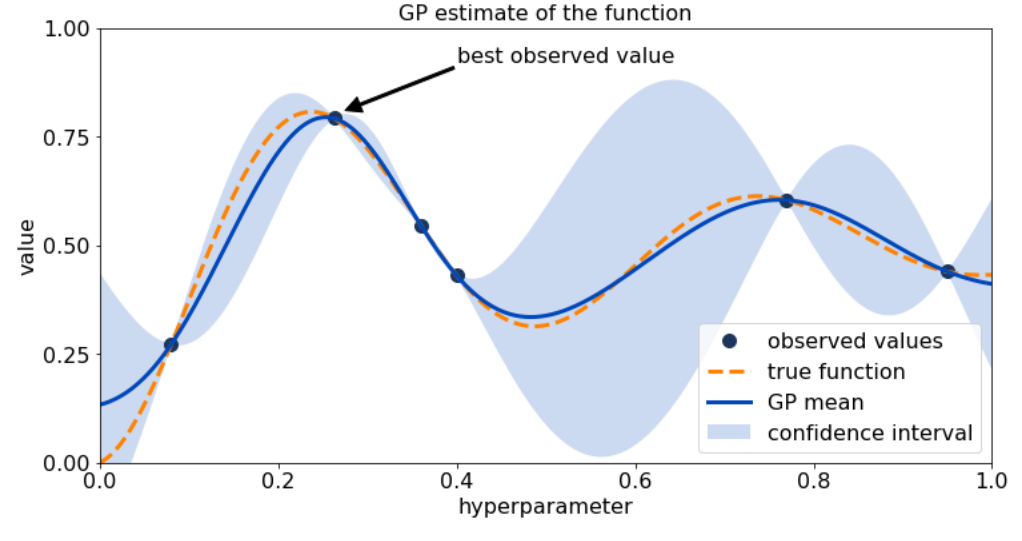
Step 3와 Step 4를 특정 횟수만큼 반복하게 되면 대체 모델이 불확실성이 개선되고 점차 정확한 최적 함수 추정이 가능하게 됨.
'ML' 카테고리의 다른 글
| [머신러닝/사이킷런] 데이터 가공: 언더&오버 샘플링, 로그 변환, 이상치 제거 (0) | 2025.02.24 |
|---|---|
| [머신러닝/사이킷런] 앙상블 학습(분류): 스태킹(Stacking) (0) | 2025.02.21 |
| [머신러닝/사이킷런] 앙상블 학습(분류): 부스팅(GBM, XGBoost, LightGBM) (0) | 2025.02.17 |
학습 자료: 파이썬 머신러닝 완벽 가이드(개정2판), 위키북스
Grid Search 방식의 단점
하이퍼 파라미터 튜닝 중 Grid Search 방식은 튜닝해야 할 하이퍼 파라미터 개수가 많을 경우 최적화 수행 시간이 오래 걸린다는 단점이 존재한다. 여기에 개별 하이퍼 파라미터 값의 범위가 넓거나 학습 데이터가 대용량일 경우에는 최적화 시간이 더욱 늘어나게 된다.
XGBoost나 LightGBM 등 하이퍼 파라미터 개수가 다른 알고리즘에 비해 많은 모델은 실무의 대용량 학습 데이터에 Grid Search 방식을 적용하면 많은 시간이 소요될 수 있다.
베이지안 최적화
개요
목적 함수 식을 제대로 알 수 없는 블랙 박스 형태의 함수에서 최대 또는 최소 함수 반환 값을 만드는 최적 입력값을 가능한 적은 시도를 통해 빠르고 효과적으로 찾아주는 방식
베이지안 확률에 기반을 두고 있는 최적화 기법
베이지안 확률이란?
새로운 데이터 B가 주어졌을 때, 기존에 알고 있던 사전 확률 P(A)을 업데이트하여 사후 확률 P(A∣B)을 계산하는 과정
베이지안 최적화는 새로운 데이터를 입력받았을 때 최적 함수를 예측하는 사후 모델을 개선해 나가면서 최적 함수 모델을 만들어 낸다.
베이지안 최적화를 구성하는 두 가지 중요 요소
1. 대체 모델(Surrogate Model): 획득 함수로부터 최적 함수를 예측할 수 있는 입력값을 추천 받은 뒤 이를 기반으로 최적 함수 모델을 개선
2. 획득 함수(Acquisition Function): 개선된 대체 모델을 기반으로 최적 입력값을 계산
(하이퍼 파라미터 튜닝에서는 입력값=하이퍼 파라미터)
=> 대체 모델은 획득 함수가 계산한 하이퍼 파라미터를 입력받으면서 점차적으로 개선되며, 개선된 대체 모델을 기반으로 획득 함수는 더 정확한 하이퍼 파라미터를 계산
과정
Step 1: 최초에는 랜덤하게 하이퍼 파라미터들을 샘플링하고 성능 결과를 관측. 아래 그림에서 검은색 원은 특정 하이퍼 파라미터가 입력되었을 때 관측된 성능 지표 결괏값을 뜻하며 주황색 사선은 찾아야 할 목표 최적함수.
Step 2: 관측된 값을 기반으로 대체 모델은 최적 함수를 추정. 아래 그림에서 파란색 실선은 대체 모델이 추정한 최적 함수. 옅은 파란색으로 되어 있는 영역은 예측된 함수의 신뢰 구간. 최적 관측값은 y축 value에서 가장 높은 값을 가질 때의 하이퍼 파라미터
Step 3: 추정된 최적 함수를 기반으로 획득 함수는 다음으로 관측할 하이퍼 파라미터 값을 계산. 획득 함수는 이전의 최적 관측값보다 더 큰 최댓값을 가질 가능성이 높은 지점을 찾아서 다음에 관측할 하이퍼 파라미터를 대체 모델에 전달.
Step 4: 획득 함수로부터 전달된 하이퍼 파라미터를 수행하여 관측된 값을 기반으로 대체 모델은 갱신되어 다시 최적 함수를 예측 추정
Step 3와 Step 4를 특정 횟수만큼 반복하게 되면 대체 모델이 불확실성이 개선되고 점차 정확한 최적 함수 추정이 가능하게 됨.
'ML' 카테고리의 다른 글
| [머신러닝/사이킷런] 데이터 가공: 언더&오버 샘플링, 로그 변환, 이상치 제거 (0) | 2025.02.24 |
|---|---|
| [머신러닝/사이킷런] 앙상블 학습(분류): 스태킹(Stacking) (0) | 2025.02.21 |
| [머신러닝/사이킷런] 앙상블 학습(분류): 부스팅(GBM, XGBoost, LightGBM) (0) | 2025.02.17 |